
アテナってなんかいいよね? Amazon Athena で知恵者の梟が S3 から戦略的にデータを取得する話
はじめに
猫とキャンプと野球観戦と AWS が大好きな旦那、LeoSaki です。モフモフしたい。
タイトルはあまり気にするな。アテナが出てきたらなんとなく梟をイメージするのは厨二ですか?
アテーナー(古代ギリシア語:Ἀθηνᾶ, Athēnā、イオーニア方言:Ἀθήνη, Athēnē アテーネー、ドーリス方言:Ἀθάνα, Athana アターナー、叙事詩体:Ἀθηναίη, Athēnaiē アテーナイエー)は、知恵、芸術、工芸、戦略を司るギリシア神話の女神で、オリュンポス十二神の一柱である。アルテミス、ヘスティアーと同じく処女神である。
女神の崇拝の中心はアテーナイであるが、起源的には、ギリシア民族がペロポネーソス半島を南下して勢力を伸張させる以前より、多数存在した城塞都市の守護女神であったと考えられている。ギリシアの地に固有の女神だが、ヘレーネス(古代ギリシア人)たちは、この神をギリシアの征服と共に自分たちの神に組み込んだのである。
日本語では主に長母音を省略してアテナ、アテネと表記される場合が多い。
業務で Amazon Athena を利用することが多いので、知識の定着のためのアウトプットのために、書いてみようと思った次第。
今回できること
- Amazon Athena を利用して、S3 に置いた CSV ファイルからデータを取得します
Amazon Athena とは?
Amazon Athena
Amazon Athena はインタラクティブなクエリサービスで、Amazon S3 内のデータを標準 SQL を使用して簡単に分析できます。Athena はサーバーレスなので、インフラストラクチャの管理は不要です。実行したクエリに対してのみ料金が発生します。
Athena は簡単に使えます。操作は簡単で、Amazon S3 にあるデータを指定し、スキーマを定義し、標準的な SQL を使用してクエリの実行を開始するだけです。多くの場合、数秒で結果が出てきます。Athena を使用すると、分析用データを準備するための複雑な ETL ジョブは不要になります。これによって、誰でも SQL のスキルを使って、大型データセットをすばやく、簡単に分析できるようになります。
Athena は初期状態で AWS Glueデータカタログと統合されており、さまざまなサービスにわたるメタデータの統合リポジトリを作成できます。データソースのクロールとスキーマの解析、新規および修正したテーブル定義とパーティション定義のカタログへの入力、スキーマのバージョニング保持が可能です。
簡潔に説明すると、サーバーレスでちょっとした操作で S3 にあるデータを SQL で分析することができて使った分しかお金がかからない凄いやつ、です。
業務で数億行のデータ分析を行っているのですが、結果が出るまでにかかる時間は 30 ~ 40 秒程度。毎月同じクエリで分析するような案件ならば、AWS の他サービスと組み合わせることで、朝出勤したら結果が出力されているようにも出来ちゃいます。Amazon Athena の利用料金だけで言うと、数千円。とてもリーズナブルでとても強力な凄いやつです。
Amazon Redshift との違い
よく聞かれます。
厳密にはちょっと違うのですが、Amazon Athena は、データレイクをクエリできるやつ、Amazon Redshift は、データウェアハウスをクエリできるやつ、と答えることが多いです。
もう少し深堀すると、Amazon Athena は、構造化されていないデータにクエリできるやつ、Amazon Athena は、構造化、半構造化されたデータにクエリできるやつ、です。
データレイクやデータウェアハウス、構造化、半構造化について説明を始めるとおおごとになるので、ご自身でお調べくださいませ。
Amazon Athena を利用する前の下準備
データを用意する
数億行のデータなんて、すぐに用意できません。今回は、「データカタログサイト」から公開されているデータを適当にとってきました。

所有者コード(自動車登録関係)の CSV ファイル – 34,567行
https://www.data.go.jp/data/dataset/mlit_20161206_0080

Amazon Athena でテーブルを作成する際に、CSV ファイルの情報が必要になってきます。確認する方法の一例です。
CSV ファイルを右クリックして「プログラムから開く」を選択し、テキストエディタで開きます。(※さくらエディタで開いた画像)
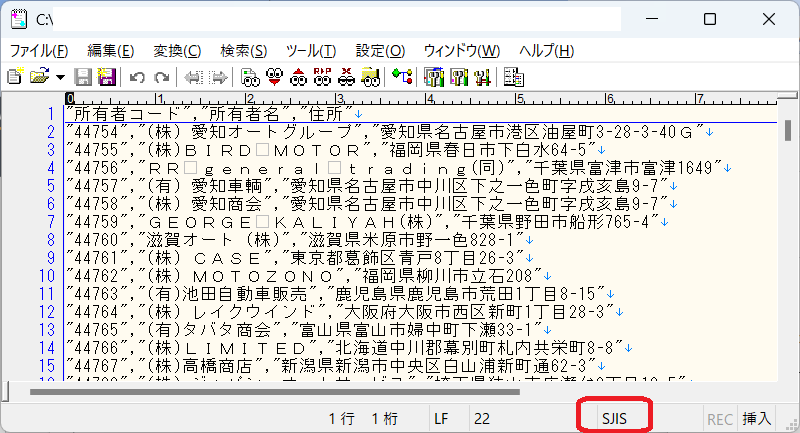
文字コードは「SJIS」で二重引用符「あり」のファイルであることが確認できます。
文字コード「SJIS」で二重引用符「あり」の場合、Athena でエンコーディング後、二重引用符「あり」の状態で出力させた後、SQL で二重引用符を取り除くしか方法がありません。そのため、ここで文字コードを「UTF-8」に変更しておきます。
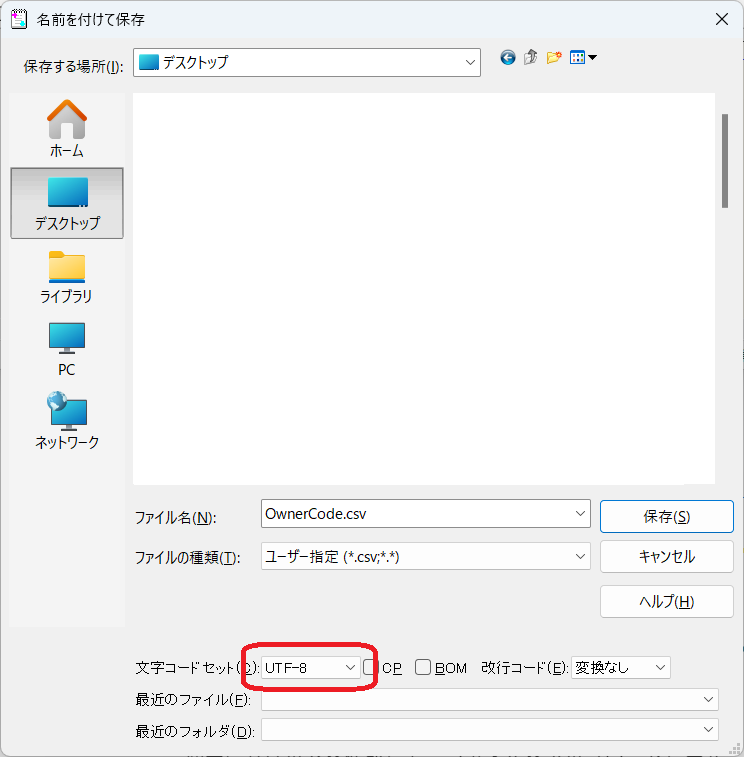
「ファイル」→「名前を付けて保存」
「SJIS」を「UTF-8」に変更して保存する
S3 にデータを入れる
適当にバケットを作成して、ファイルをアップロードします。
データの準備はこれだけです。取得した CSV ファイルを S3 バケットに突っ込むだけ。
Amazon Athena での作業
Amazon Athena のコンソールです。料金は・・・スキャンスタデータ量 1 TB で 5 USD(東京)だと⁉ 安い!
初回のみ必要な作業
この後の作業で、Amazon Athena で実行したクエリ結果を保存するバケットを指定する必要があります。S3 で適当な名前のバケットを作成しておいてください。
クエリエディタを選択して開きます
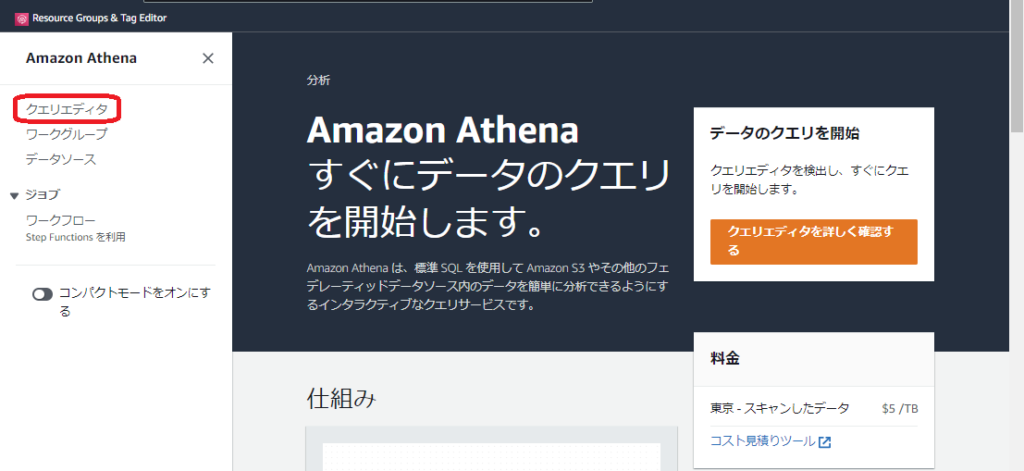
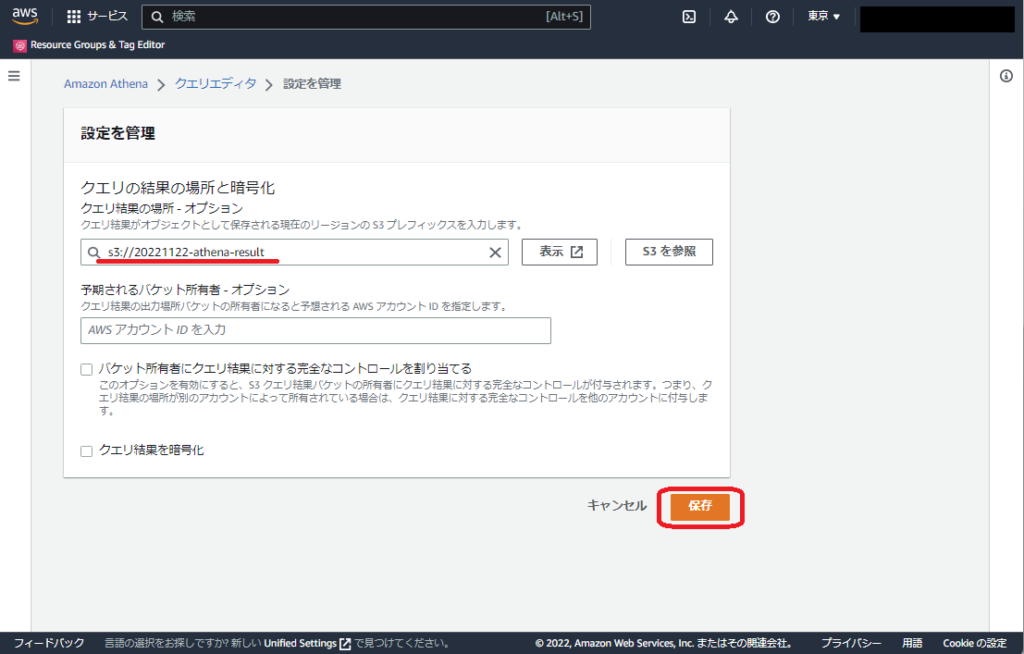
クエリ結果の場所を設定する ~ 「設定を編集」をクリックします
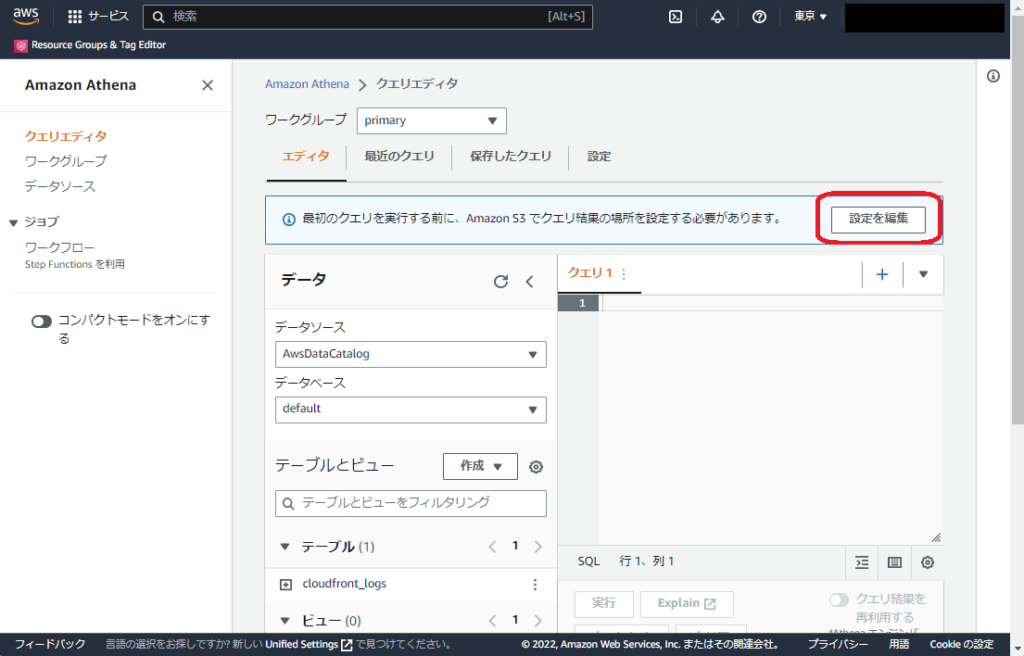
S3 を参照を選択します
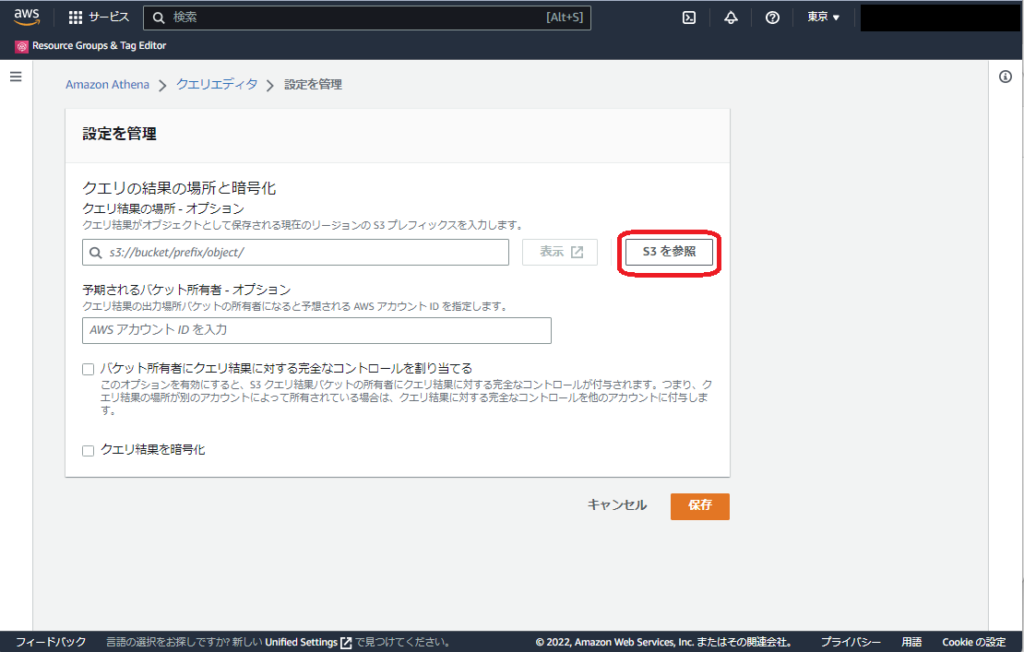
用意しておいた S3 バケットを選択してください
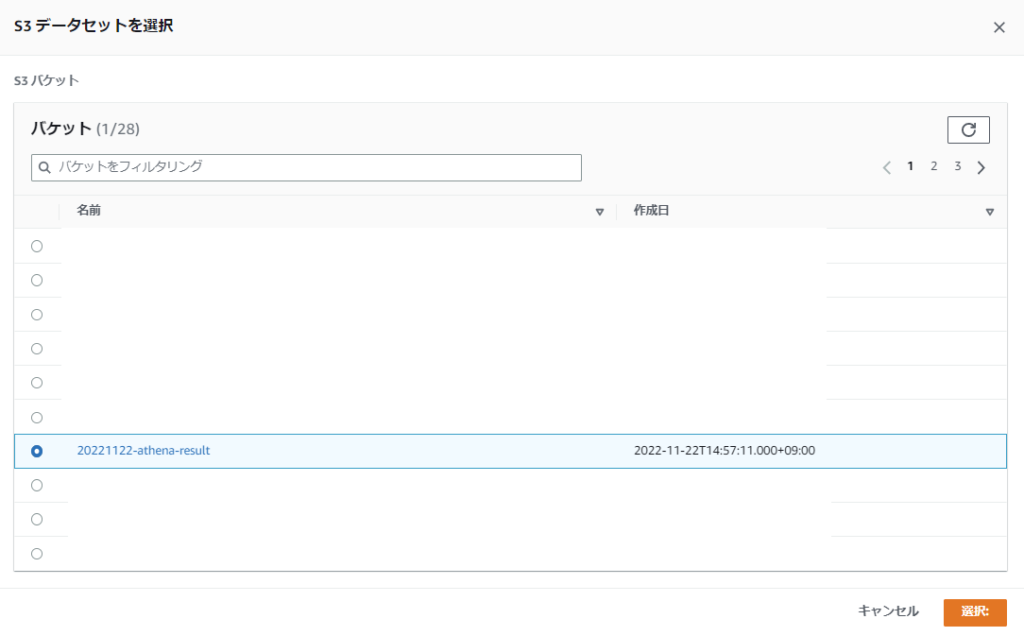
確認して間違いがなければ、保存を選択します
これで、初期設定が完了です
スキーマの定義
Amazon Athena の説明には、こう書かれている。わかりやすく言うと、テーブルの作成。
直接クエリ(Create table)を書いて作成することも可能だけれど、今回用意した CSV の規模であれば、もっと簡単にテーブルの作成を行うことができる。
作成をクリックして、「S3 バケットデータ」を選択する
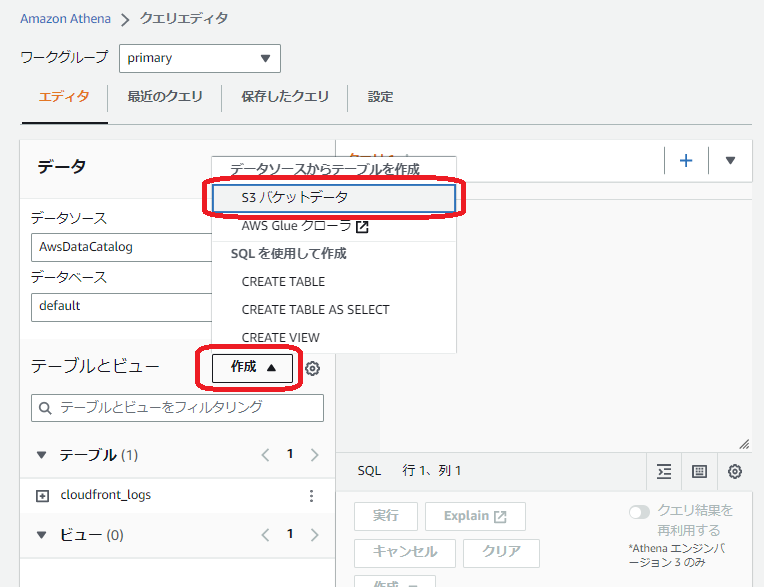
テーブル名をわかりやすく。ハイフンは使えないので注意
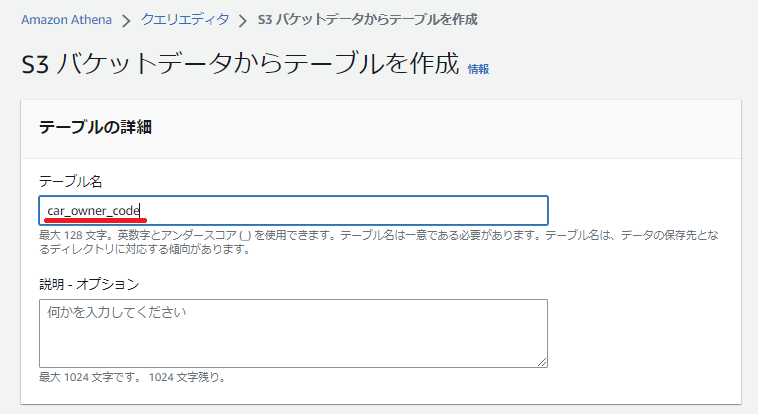
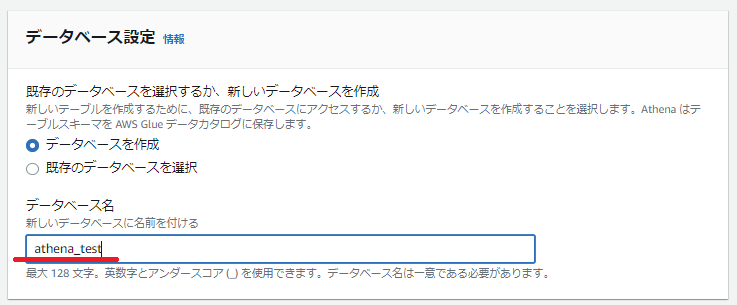
今回は新しくデータベースを作成しました
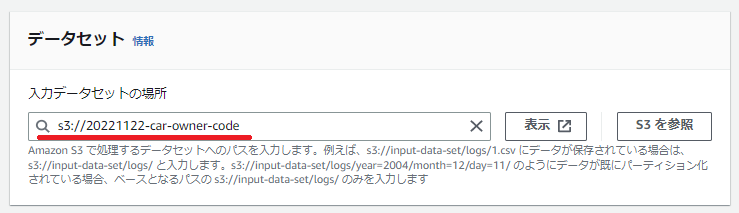
データセットの場所は、最初に作成したデータが入っている場所
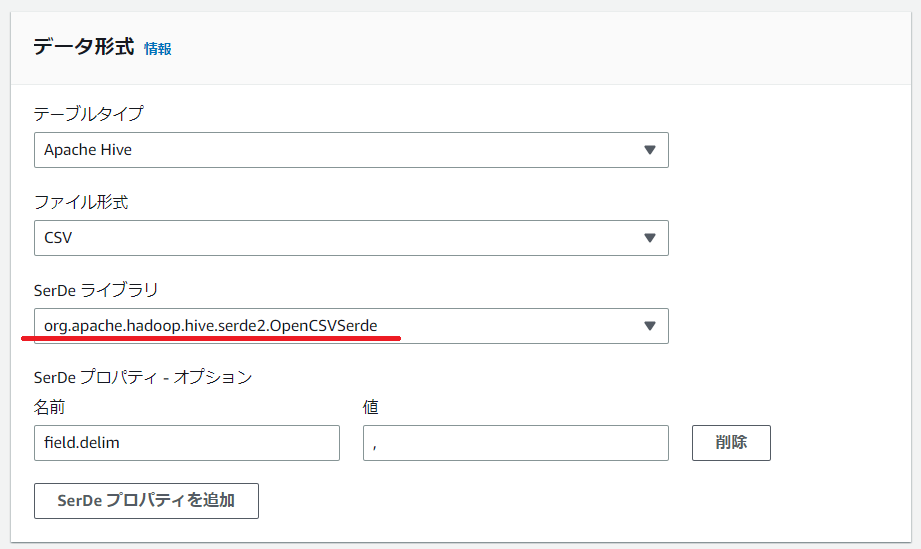
二重引用符「あり」の場合の設定です
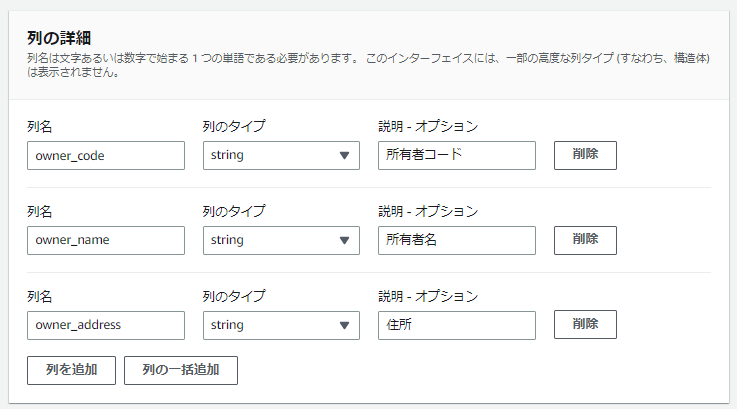
所有者コード(自動車登録関係)の CSV ファイルに合わせて列を作成
※重要※ ヘッダー部の読み込みをスキップさせる設定を追加します
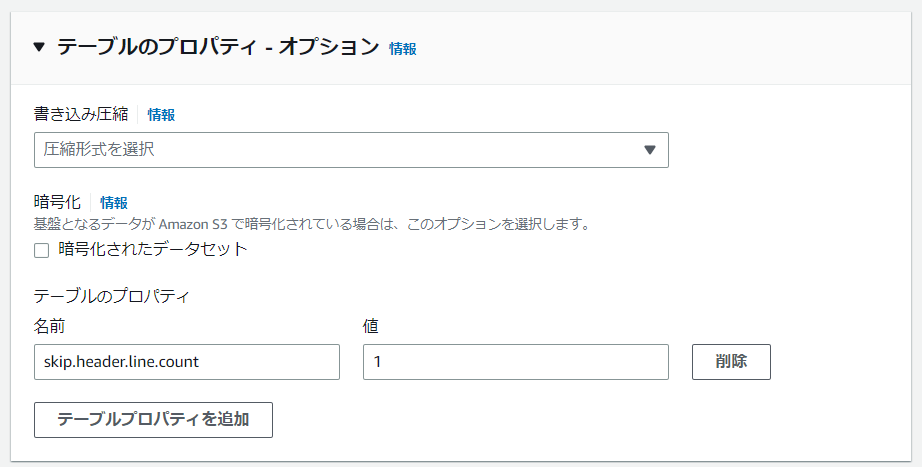
確認して問題なさそうでしたら、テーブルを作成をクリック
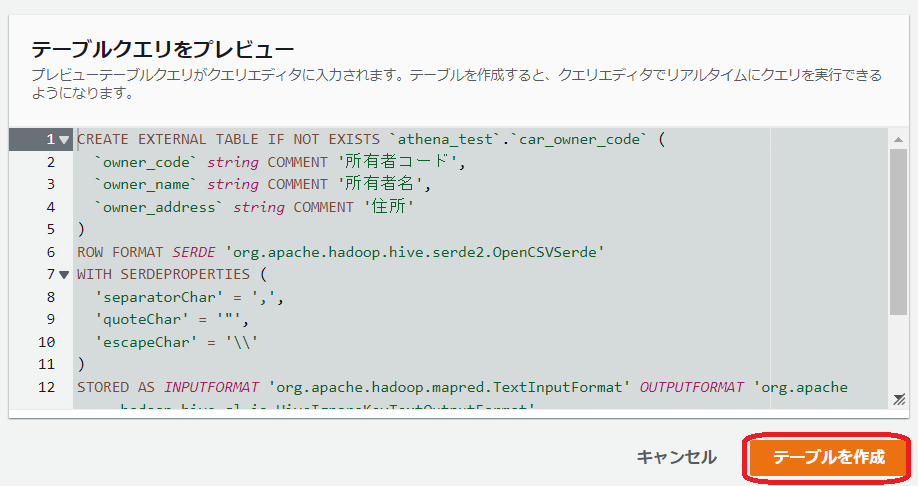
クエリは成功しました!

確認
適当なクエリを書いて、実行を押してみます
SELECT *
FROM car_owner_code
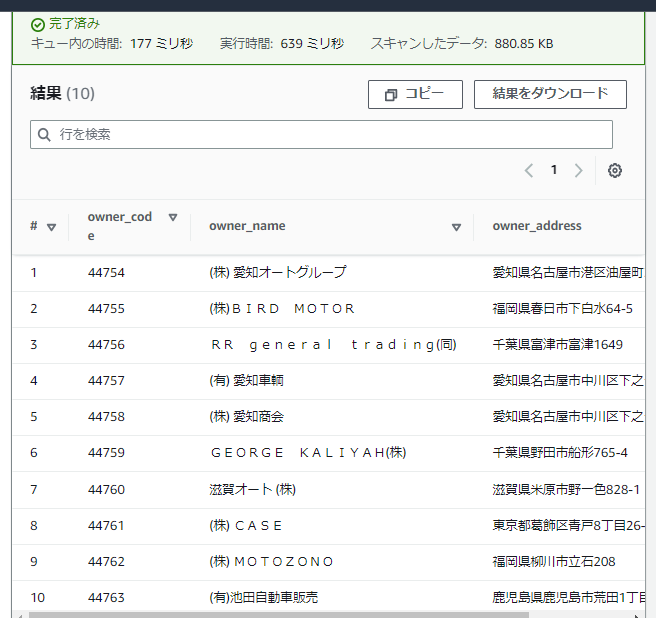
LIMIT 10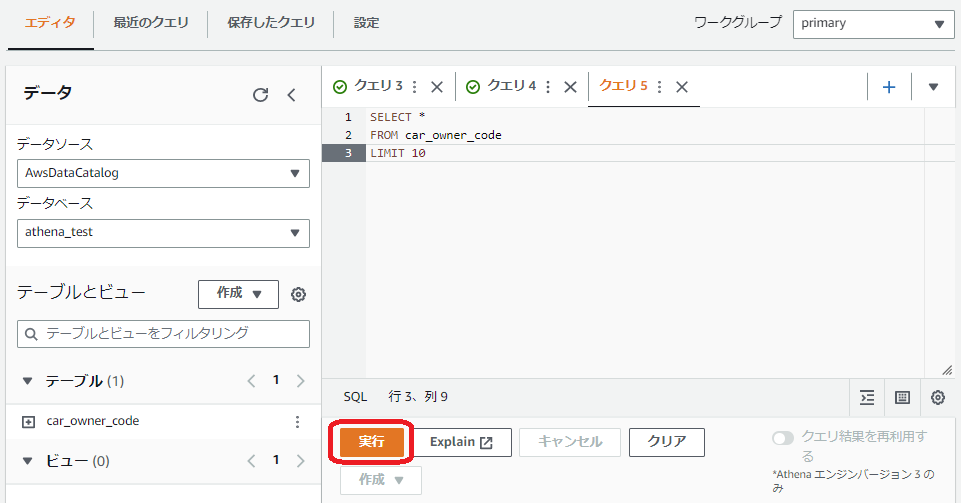
問題なさそうですね!
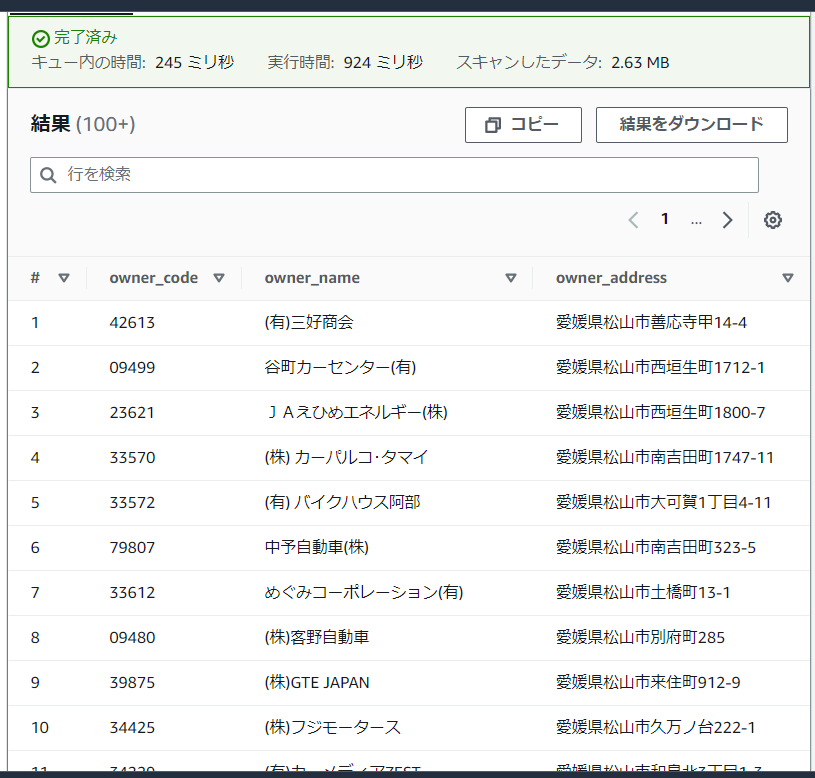
owner_address が「愛媛県松山市」ではじまるものを検索してみます
SELECT *
FROM car_owner_code
WHERE owner_address like '愛媛県松山市%'このくらいであれば、実行時間は 1 秒未満です!
最後に
普段、UTF-8 にエンコーディングされているデータばかりを取り扱っているため、SJIS の CSV ファイルに少し手間取りました。SJIS + 二重引用符「あり」の CSV ファイルは、Create table だけで処理することはできないようです。
S3 に CSV ファイルをアップロードして、すぐに分析に進めることで、業務効率が一気に上がりました。そして、費用対効果も大きい! 今回はやりませんでしたが、パーティションを作成することもできます。そのために必要なのは S3 バケットを正確に管理しておくことだけ。多くの場合、機械的に S3 バケットへデータを流すことになると思いますので、あまり問題にはなりません。
どこにも戦略的な部分がない内容になってしまった。オチが思いつかない。
Amazon Athena を是非、使ってみてください。
引き続き、よろしくお願いいたします!